Ecoacoustics SDM use case

Summary:
Open EcoAcoustics has a vision to “enable open science and conservation through the development and promotion of open access ecoacoustics technologies, methodologies and standards”. Biodiversity inventories and monitoring in Australia are difficult due to the vast areas of remote areas few people visit which are confounded by some species which are exceedingly difficult to detect. Imagine a 10 to 20 fold decrease in the time required in the field to generate verifiable occurrence data for species which vocalise, perhaps only occasionally. While this is clearly a huge challenge, the tools being developed by QUT and the stakeholders involved in Open EcoAcoustics are demonstrating how this can be achieved. Below we highlight how ecoacoustics data can be a game changer for our understanding of species distributions.
By – Dr Andrew Schwenke, QUT & Dr Rob Clemens

The Australian Acoustic Observatory, Hoot detective, & the impact of good data on species distribution models
Introduction:
The Australian Acoustic Observatory (A2O) is a continental-scale acoustic sensor network that provides data for hundreds of acoustic sensors across seven Australian ecoregions. This data is freely available to researchers, citizen scientists, and the general public, for use under CC BY 4.0 licence. More information about the A2O can be found in a paper published in Methods in Ecology and Evolution (Roe at al., 2021). For National Science Week in 2021, a partnership between ABC Science, the Australian Acoustic Observatory, Queensland University of Technology and the University of New England, formed the Hoot Detective project. This was a citizen science project that used recordings from the Australian Acoustic Observatory, resulting in the identification of 23,568 owl calls by members of the public. There are a variety of advantages to this kind of continental scale data (Guerin et al. 2020) and those advantages directly apply to questions looking to predict a species distribution.
First, occurrence data for most fauna in Australia are not systematically collected at geographic scales. Most data for species that vocalise are highly biased with the most sampling done near the handful of urban areas in what is otherwise the remote continent of Australia. Dealing with sampling bias in species distribution modelling is one of the biggest challenges to generating optimal results. However, these sampling issues can be virtually eliminated by deploying ecoacoustic sensors based on sampling protocols that are representative of both geographic and environmental space. The Australian Acoustic Observatory achieves this at a continental scale, with around 360 continuously operating acoustic sensors deployed across Australia in a variety of unique ecosystems.
Second, while there will always be variation in detection probability in any fauna survey, ecoacoustic data takes a huge leap toward delivering standardised data. In species distribution modelling, the complications arising from variable detection rates have led many researchers to model detection, using something called occupancy modelling. Indeed, occupancy modelling may be helpful when accounting for variable detection rates between sites and sensors when working with acoustic data. But when using acoustic sensors, survey effort is much more standardised than in human observation data, which can reduce or eliminate the need to use such techniques. Furthermore, species identifications from ecoacoustic data are verifiable and can exist as a persistent record for future use and evaluation.
Third, the field of species distribution modelling has thousands of papers related to using presence-only modelling methods, or using binomial methods (presence / absence) with pseudo-absence data. Pseudo-absence data attempts to make the best possible guess as to where species might be absent or at the least ensures that random pseudo-absence points are not selected in areas where there is zero chance that the species might be present. As acoustic sensors are increasingly deployed an understanding of detection probability begins to emerge for different sensors and different species. In other words, we can determine how long a sensor should be left out before we are nearly certain that the species of interest is not present. Once a sensor is left out the required amount of time, a true absence location is generated, and such data have explosive impacts on how well you can model species distributions using a variety of both statistical and machine learning techniques.
Fourth, an acoustic device records every single call a species makes near a monitor. While human observation data can also provide such data, it would be a massive undertaking to deliver that kind of data at scale. Yet, for many species that vocalise, one can expect call rates to be highest in areas and times of year when species are breeding, and vocalisation rates may even be higher in areas of higher quality habitat (at least for some species). Modelling the distribution of call frequency or abundance has been done far less in the literature than presence only modelling, yet the potential insights from such models are clear. For select species, an area with more calling might be more important for the species, and an area with more individuals calling might be relatively more important than the more silent areas.
There are caveats around all of this of course, but below we demonstrate the kinds of results that can be generated with presence absence vs presence only data, and the insights that could be gained from predicting the spatial variation in call frequency. We argue the benefits are clear, and ask you to help deliver this kind of data at scale.
Methods:
The data were obtained from the historical Hoot Detective project, and consisted of annotations for five owl species: Masked Owl (Tyto novaehollandiae), Eastern Barn Owl (Tyto javanica), Barking Owl (Ninox connivens), Powerful Owl (Ninox strenua), and Southern Boobook (Ninox boobook). All data, including audio recordings, annotations, and associated sensor metadata, is available for download and use from the A2O data portal. A GitHub repository detailing the complete methods for preparing the Hoot Detective data, prediction layers, and running preliminary SDM analyses with R is available.
Data preparation:
The Hoot Detective project resulted in 28723 segments of annotated audio, from 37 sensors. Each segment of audio was 10 seconds in length, resulting in a total of just under 80 hours of annotated audio. Audio segments came from most days spanning between June, 2019, until July, 2021 (Figure 1). These annotations were summarised in R to get occurrence data for each species, which included determining if at any point the target species was recorded (presence) or was absent from recordings (absence).
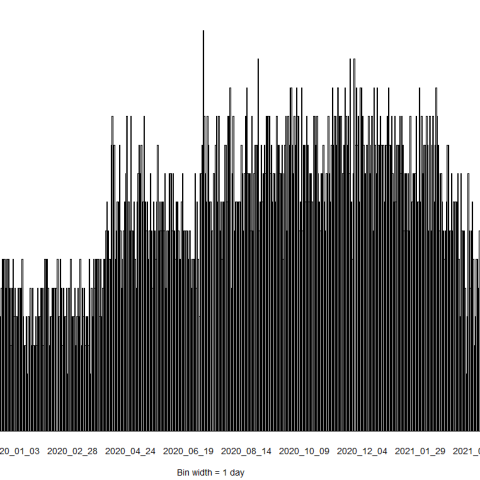
Figure 1. Histogram demonstrating total frequency of annotated audio segments per day in the Hoot Detective data set.
A Powerful Owl presence was recorded in Western Australia, which is quite far outside of the recognised distribution. Therefore, Powerful Owl records were filtered further, using a buffered boundary of the known distribution extent derived from ALA records, to remove these potentially anomalous records.
The A2O uses a paired sensor design, with four sensors per site. The distance between sensors is typically within 500m to 5000m. Therefore, we first attempted to use environmental layers at a high spatial resolution (25m), to capture fine scale variation between proximate sensors.This came at a high computer processing cost. Even working with buffered extents, and using a Big Data PC, the process was slow, highlighting the challenges of using such high resolution data. As a result, we decided to instead use a 250m resolution for preliminary analyses in R, and a 1000m resolution on the ecocommons platform. To get a raster stack for the extent of Australia, the terra package in R was used to crop and mask layers to a vector of the Australian boundary. Layers were then resampled from their original resolution where necessary to 250m, using bilinear interpolation for continuous bioclim data, mean for forest canopy and height, and nearest neighbour for categorical data. All layers were projected to the project CRS (EPSG: 4326). For Powerful Owl, the raster stack was cropped and masked to the buffered boundary extent representing the known distribution.
Analysis
Powerful Owl presence data were used to extract environmental variable values from eastern Australia, and the resulting presence data and environmental rasters were used in a Maxent model in R (see code).
Presence only vs presence absence comparisons were made within the EcoCommons platform. Evironmental predictors were at 1 km resolution and included the ANU Bioclim variables, 5,6,13 & 17, run in BioClim and SRE for presence only, and ANN, RF, & MARS. First, the presence only occurrence records were used to generate a BioClim model prediction using default settings. Then the presence absence data were used in an Artificial Neural Network (ANN) model, Random Forest model, and multivariate adaptive regression splines (MARS).
To examine the potential of predicting call frequency across Australia we selected the Southern Boobook which was recorded at all but one station (mean 137 vocalisations, range 0 to 993). We then extracted raster grid values from the two forest area variables, bioclim variables 5,6 and 17, and NVIS, a national vegetation classification. We then ran a Boosted regression tree (BRT) model specifying a Poisson distribution (see code).

Figure 2. Distribution of Powerful Owl estimated from Australian Acoustic Observatory data using a Maxent model.

Figure 3. A presence-only distribution BioClim model for Masked Owl based on occurrence data for the Australian Acoustic Observatory.
Results
The 37 monitoring stations that were included in the Hoot Detective project are spread across large areas of Australia, so it is perhaps not surprising that data availability and results varied between species. For example, the Powerful Owl which is only found in eastern Australia had relatively few locations where they were recorded. Chance resulted in more detections of Powerful Owl in southeast Queensland in observatory data, and that bias is reflected in attempts with multiple methods to predict their distribution using only observatory data. Nonetheless, the presence-only model MaxEnt proved to be the best at approaching predictions of the actual distribution of Powerful Owl in eastern Australia (Figure 2).
When comparing presence only data with presence / absence data, again results varied by species, but were most interesting for a species that had close to the same number of presence and absence data available, the Masked Owl. Using this owl’s presence only data in a Bioclim model resulted in a reasonable approximation of geographic distribution in southern Australia (Figure 3). However, that model completely failed to predict the presence of this owl in much of northern Australia. When presence absence data was run through a Artificial Neural Network model, the predictions included all of northern Australia (Figure 4) and were much more closely aligned to the known continental distribution of Masked Owl.
The mapped frequency of southern boobook suggests that it would be possible to predict areas where these owls call more (Figure 5). The results demonstrated some reasonable patterns, such as increased call frequency along what might be creeks or waterways in the outback, while the lowest call frequencies were in outback deserts. The high call frequency in SW WA also looked reasonable, but the lack of similar high call frequency areas in much of eastern Australia are likely due to insufficient sampling in this region.

Figure 4. The predicted distribution of Masked Owl based on presence-absence data trained using a Artificial Neural Network model. Notice the big difference between presence only (Fig. 2) and presence-absence.
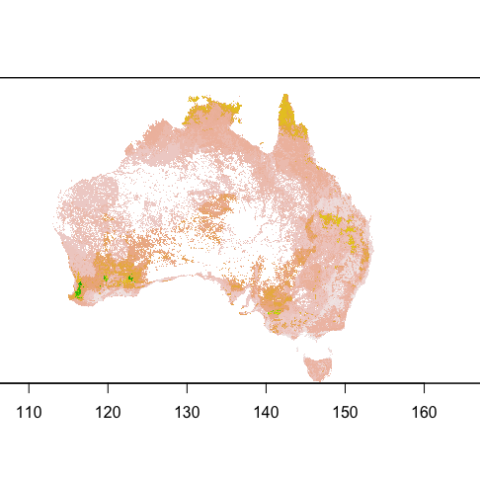
Figure 5. The predicted frequency of Southern Boobook calls based on the number of calls recorded at each station in the Australian Acoustic Observatory and trained using a boosted regression tree with a Poisson distribution.
Discussion:
It was surprising how well some of the data predicted continental distributions despite there being relatively few records available (< 37 for each species). It was also striking how vastly different predictions were when using presence only vs presence absence data. Finally, the variation in predicted call frequency of the southern Boobook across Australia suggests that the metric of call frequency may be a useful indicator of habitats that get more use, potentially related to habitat quality or breeding activity.
Initial attempts to model with 25m resolution proved too much data to handle, but further work to tile data extractions and predictions would likely allow such high resolution predictions, and while not useful at the continental scale modelled here, there were some stations that were fairly close together, and with fine resolution data it might be possible to tease apart the within cluster variation in presences or frequency of presences.
As acoustic monitoring activities continue to grow we demonstrate how the absence data acoustic sensors can deliver and the call frequency can produce game changing results when looking to understand species distributions.
It is well established that acoustic monitoring can provide significant ecological insights, across both broad spatial and temporal scales. As acoustic monitoring activities continue to grow, we demonstrate that when such data is annotated, whether by using recognisers, or through citizen science projects such as Hoot Detective, the absence data acoustic sensors can deliver and the call frequency metric provided, can produce game changing results when looking to understand species distributions. This process is further aided by the use of online platforms such as EcoCommons, which allows practitioners and researchers to seamlessly examine their data using a wide range of modelling tools and trusted datasets.

Figure 6. Distribution of Powerful Owl estimated from all BirdLife data in southeast Queensland combined with a layer of the unions between the areas that captured geographic sampling or sampling of environmental space. High values of uncertainty are equivalent to low sampling coverage.

Figure 7. A presence-only Maxent distribution model of Powerful Owl breeding locations based on occurrence data from BirdLife Australia. Model evaluvtion: AUC > 0.95

Figure 8. A presence-only Maxent distribution model of Powerful Owl breeding locations and locations where acoustic sensors have been deployed. We know owls are in many of these areas, but we have not confirmed breeding yet. If we were to detect breeding in all the areas, look how much the map changes. Data matters. Model evaluvtion: AUC > 0.95
Putting uncertainty on the map and the huge change to predicted distributions if ecoacoustic data are used to survey those areas with the greatest uncertainty. – By Dr Robert Clemens
In species distribution modeling (SDM), researchers are often using data that have not been systematically collected throughout their area of interest. This creates a variety of challenges to generating results that are of sufficient quality to answer the researcher’s specific question. Indeed there are a variety of rigorous methods that are used to successfully generate SDM results that are fit for purpose. However, the outputs often include a map, and we live in a world where Google Earth and other spatial mapping is highly precise. The mapped distributions being generated by researchers are often interpreted as being accurate by audiences who may be looking to use these maps for different purposes than they were intended. When areas are found to be inaccurately mapped, the credibility of the SDM output is questioned, despite the SDM output being appropriate for its intended purpose. Here we demonstrate one simple way to put uncertainty on the map in hopes of sparking more explorations into the presentation of SDM results (Figure 6).
Inspiration for the idea of mapping uncertainty came from the winners of the “Venables Award for New Developers of Open Source Software for Data Analytics sponsored by the ARDC” which celebrated a software package that provides functionality for visualising uncertainty in spatial data.
Code for bivariate legend and map
https://rfunctions.blogspot.com/2015/03/bivariate-maps-bivariatemap-function.html
Code with links to example data based on Powerful Owl locations and predicting where they are found in southeast Queensland.
There are a variety of ways to map uncertainty and to measure it. We encourage others to share their methods. Some measures of uncertainty in modelled predictions are often included in the mapped predictions based on cross-validation or boot-strapping results, and through data validation with uncertain data. In our simple example, we highlight the joint intensity of geographic sampling and sampling of environmental space. We did this by taking the inverse, scaled number of bird surveys in each grid cell to represent sampling intensity in geographic space. We then calculated surface range environmental envelopes in five deciles based on the occurrence data, and environmental data we felt would be important for Powerful Owls. We then summed those decile envelope maps and scaled and took the inverse of the result. The final step to generate a map reflecting where uncertainty was greatest, or where sampling was the least representative involved taking the statistical union of the geographic uncertainty layer and the environmental uncertainty layer.
Mapping uncertainty in species distribution model outputs provides a useful understanding of where predictions are most likely wrong and it also provides a business case for additional monitoring in select locations provided there is value in decreasing uncertainty in those areas.
We also demonstrate the enormous impact new data can have on the resulting mapped species distribution and remind users of the utility of ecoacoustic monitoring data to affordably add certainty to those parts of the map where predictions are most uncertain. In (Figure 7) we develop predictions of breeding areas for Powerful Owl based on BirdLife data using Maxent. We recently deployed acoustic sensors at > 25 locations in an attempt to identify breeding locations (chicks call loudly after leaving the hollow). We know owls are active in many of these areas but we have not yet identified breeding. However, if we imagine we identified breeding in all locations where sensors were deployed, notice the large change in predicted distribution (Figure 8).
Follow us for news & events
Follow us on LinkedIn for updates, news and upcoming events!
Our partners

EcoCommons Australia partners with the Australian Research Data Commons (ARDC), which is supported by funding from the National Collaborative Research Infrastructure Strategy (NCRIS) https://doi.org/10.47486/PL108.